引言:大數(shù)據(jù)時代的核心挑戰(zhàn)
在當(dāng)今數(shù)據(jù)驅(qū)動的時代,企業(yè)面臨著前所未有的數(shù)據(jù)洪流。海量的、高速增長的、多樣化的數(shù)據(jù)資產(chǎn),既是寶貴的金礦,也是巨大的技術(shù)挑戰(zhàn)。成功挖掘數(shù)據(jù)價值的關(guān)鍵,在于構(gòu)建一個穩(wěn)健、高效、可擴展的大數(shù)據(jù)架構(gòu)。本文將系統(tǒng)性地解析大數(shù)據(jù)架構(gòu)的完整生命周期,特別聚焦于作為基礎(chǔ)支撐的數(shù)據(jù)處理與存儲服務(wù),并探討其如何為高級分析乃至深度學(xué)習(xí)鋪平道路。
第一部分:架構(gòu)起點——多源數(shù)據(jù)獲取與攝取
大數(shù)據(jù)架構(gòu)的第一步是數(shù)據(jù)的獲取與攝取(Data Ingestion)。數(shù)據(jù)可能來自四面八方:
- 內(nèi)部系統(tǒng):如業(yè)務(wù)數(shù)據(jù)庫(MySQL, PostgreSQL)、應(yīng)用程序日志、ERP/CRM系統(tǒng)。
- 外部數(shù)據(jù)流:如社交媒體API、物聯(lián)網(wǎng)(IoT)傳感器數(shù)據(jù)、市場數(shù)據(jù)饋送、合作伙伴數(shù)據(jù)接口。
- 實時流與批量數(shù)據(jù):架構(gòu)需要同時支持實時流(如Kafka, Flume)和批量(如Sqoop, 定時ETL作業(yè))兩種數(shù)據(jù)攝取模式。
這一階段的核心是建立一個可靠、低延遲的“數(shù)據(jù)管道”,確保數(shù)據(jù)能夠被完整、準(zhǔn)確地從源頭傳輸?shù)街醒胩幚砥脚_。
第二部分:基石之重——數(shù)據(jù)處理與存儲服務(wù)詳解
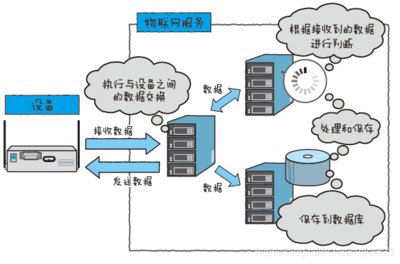
數(shù)據(jù)處理與存儲層是整個大數(shù)據(jù)架構(gòu)的基石,它決定了數(shù)據(jù)的管理效率、可用性以及上層應(yīng)用的性能。
1. 存儲是基礎(chǔ):分層存儲策略
- 原始數(shù)據(jù)湖(Data Lake):通常基于Hadoop HDFS或?qū)ο蟠鎯Γㄈ鏏WS S3, 阿里云OSS),用于低成本、持久化地存儲所有原始數(shù)據(jù),無論其結(jié)構(gòu)如何。它保留了數(shù)據(jù)的最大靈活性。
- 處理與歸檔層:對數(shù)據(jù)進行清洗、轉(zhuǎn)換后,形成結(jié)構(gòu)化的數(shù)據(jù)集,可存入數(shù)據(jù)倉庫(如Hive, Redshift, BigQuery)供分析使用。建立冷數(shù)據(jù)歸檔策略,優(yōu)化存儲成本。
2. 數(shù)據(jù)處理的核心引擎
- 批處理:以Apache Spark和MapReduce(Hadoop)為代表,適用于對海量歷史數(shù)據(jù)進行復(fù)雜、高延遲的分析與轉(zhuǎn)換。Spark憑借其內(nèi)存計算優(yōu)勢,已成為批處理的主流選擇。
- 流處理:以Apache Flink、Spark Streaming和Kafka Streams為代表,對連續(xù)的數(shù)據(jù)流進行實時或近實時的處理,用于監(jiān)控、實時儀表盤和即時響應(yīng)場景。
- 統(tǒng)一數(shù)據(jù)處理:現(xiàn)代架構(gòu)趨勢是采用像Apache Beam這樣的統(tǒng)一編程模型,允許同一套代碼邏輯在批處理和流處理引擎上運行,簡化開發(fā)。
3. 數(shù)據(jù)服務(wù)與治理
- 元數(shù)據(jù)管理:使用Atlas、DataHub等工具對數(shù)據(jù)的來源、含義、血緣關(guān)系進行追蹤和管理,確保數(shù)據(jù)的可發(fā)現(xiàn)性與可信度。
- 數(shù)據(jù)目錄與服務(wù)層:將處理好的數(shù)據(jù)以API、數(shù)據(jù)集市或數(shù)據(jù)產(chǎn)品的方式,安全、高效地提供給業(yè)務(wù)部門、數(shù)據(jù)科學(xué)家和分析師使用。
第三部分:價值升華——從數(shù)據(jù)分析到深度學(xué)習(xí)
堅實的數(shù)據(jù)處理與存儲基礎(chǔ),為上層高級分析提供了肥沃的土壤。
1. 分析與挖掘
在清洗和整合好的數(shù)據(jù)之上,可以進行:
- 交互式查詢:使用Presto、Impala等引擎進行即席分析。
- 數(shù)據(jù)挖掘與機器學(xué)習(xí):利用Spark MLlib、scikit-learn等庫構(gòu)建傳統(tǒng)的預(yù)測模型和分類模型。
2. 深度學(xué)習(xí)的舞臺
深度學(xué)習(xí)對數(shù)據(jù)架構(gòu)提出了更高要求:
- 大規(guī)模訓(xùn)練數(shù)據(jù)供給:存儲層需要能高效地向GPU集群提供海量的圖像、文本、音頻等非結(jié)構(gòu)化訓(xùn)練數(shù)據(jù)。
- 特征工程與存儲:深度學(xué)習(xí)模型依賴高質(zhì)量的特征。數(shù)據(jù)處理管道需要自動化地進行特征提取、轉(zhuǎn)換和存儲,形成可供模型快速訪問的“特征庫”。
- 模型訓(xùn)練與部署:架構(gòu)需要整合像TensorFlow、PyTorch這樣的框架,并提供從數(shù)據(jù)準(zhǔn)備、模型訓(xùn)練、評估到模型服務(wù)化(Serving)的一體化流水線,通常借助Kubeflow、MLflow等MLOps平臺實現(xiàn)。
第四部分:架構(gòu)演進與未來展望
現(xiàn)代大數(shù)據(jù)架構(gòu)正朝著云原生、存算分離、實時智能的方向發(fā)展。
- 云原生與Serverless:基于Kubernetes和云服務(wù)的架構(gòu)提供了極致的彈性與運維簡化。
- 湖倉一體(Lakehouse):如Databricks Delta Lake,融合了數(shù)據(jù)湖的靈活性和數(shù)據(jù)倉庫的管理與性能,正成為新趨勢。
- 實時化與智能化:流處理能力成為標(biāo)配,AI能力被更深地嵌入數(shù)據(jù)處理管道本身,實現(xiàn)更智能的實時決策。
###
從數(shù)據(jù)獲取到深度學(xué)習(xí),大數(shù)據(jù)架構(gòu)是一條環(huán)環(huán)相扣的價值鏈。其中,數(shù)據(jù)處理與存儲服務(wù)是承載一切的基石。它不僅是技術(shù)的堆砌,更是對數(shù)據(jù)流、計算模式與業(yè)務(wù)需求的深刻理解與平衡。構(gòu)建一個靈活、健壯、可持續(xù)演進的數(shù)據(jù)基礎(chǔ)平臺,是企業(yè)在這場數(shù)據(jù)智能競賽中贏得未來的關(guān)鍵所在。